
Atlassian Confluence is a popular collaboration tool that allows teams to create, share and manage documents, projects and knowledge. At Arionkoder, we use this platform to collect in a single place all our internal information, with pages dedicated to each of our areas, and all Arionics are invited to collaborate there.
Navigating such a huge database might be sometimes difficult. Writing a query in a box is useful, but when it comes to attachments, empty pages or general concepts, it becomes obsolete. So how to ease this search in the AI era?
That’s where a RAG system comes in handy. RAG stands for Retrieval Augmented Generation, and refers to systems that leverage Large Language Models (LLMs) to retrieve relevant documents and create human-like responses to questions. Instead of having to navigate yourself through the entire database, you simply ask a question, and an LLM identifies which pages are specifically related to that, and uses that as context to create a lovely answer. It’s like chatting with your data. Amazing, right?
Well, we’re doing that already at Arionkoder: we built AK-Bot, a Slack chatbot connected to all our internal platforms, that allows Arionics to get quick answers to their doubts while finding the data sources. In this blog post, we will elaborate particularly on our Confluence integration, and how we implemented that.
A quick overview of our back-end and the use cases
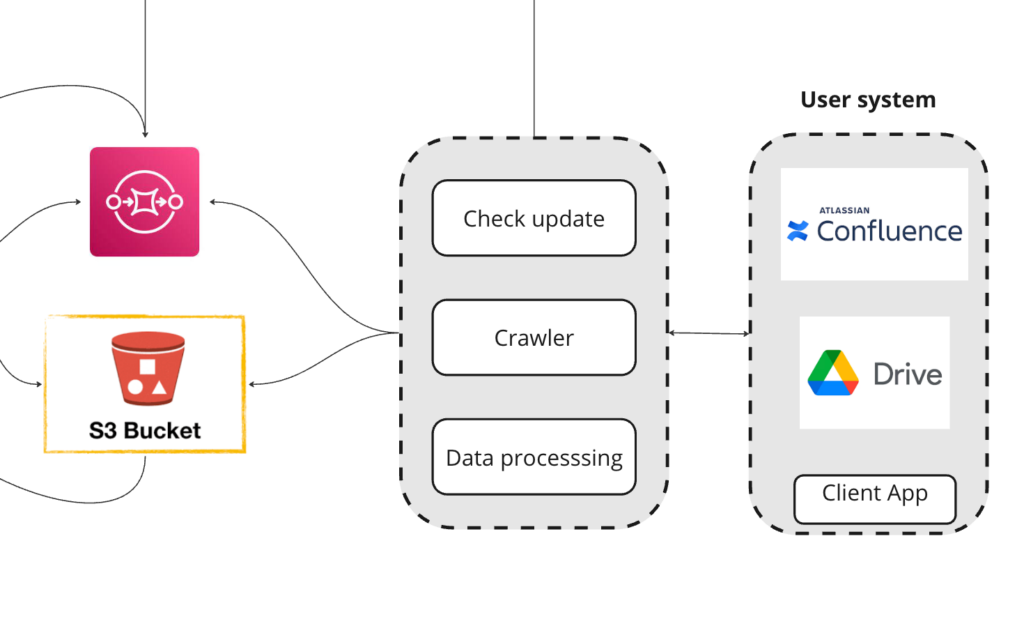
Our data pipeline has the objective of extracting data from various sources (Confluence, Google Drive, databases) and processing it, preparing the data to be consumed by our RAG application. We can work with a wide range of data formats such as text, images, PDFs and others.
The first step is to extract all the text present in the data, then we persist it in an S3 bucket and add it to an SQS queue so it can be processed in a format that our RAG application can handle.
To create our knowledge base we load the extracted data and use an embedding model to create embeddings and save it on our vector database. We have 2 use cases for our data processing layer: the first one, to upload new information to the system, and the second, to update data sources where we extract information from. If you want to know more about it, you can contact us and learn more about our customized RAG tool.
Prerequisites for Confluence Integration
In a nutshell, you will need:
- Personal access tokens: confluence personal tokens are a secure way to integrate applications into Confluence. You can create your personal access token inside Confluence by going to Settings (top right of the screen) and then clicking on Personal access tokens.
- Confluence URL: The page address of the Confluence page you want to extract the information from.
- A password: This is your password as a Confluence user.
- Namespace: The name of the space you want to extract information from.
You can check the official documentation on how to generate your token: https://confluence.atlassian.com/enterprise/using-personal-access-tokens-1026032365.html
Options for Confluence Integration
When it comes to connecting with Confluence, you have two different options for integration: you can either use Confluence API, or take advantage of RAG libraries that abstract those parts for you, such as Llama Index or Langchain.
The first option is sending your request directly to the Confluence REST API. This is probably the most powerful way to access Confluence data. The downside, however, is that the API documentation is quite complicated, and you will have to invest quite some time to learn it. Alternatively, you can take advantage of Llama Index and Langchain abstractions for Confluence, which are easier to learn and really good for the simpler uses.
In our use case, we use Langchain for ingesting the pages, and the Confluence API for handling updates.
Langchain integration for ingesting new pages
You can ingest the information using the Confluence Loader and the function loader.load using only a couple of lines of code. You shouldn’t forget here from which space you want to get the information. The standard behavior of the function is to retrieve plain text present on the page.
If you want to extract more information e.g. the attachments of the page or format information (which will be exported in markdown language), you can customize your query based on the parameters of the function. For example, if you use the flag include_attachments=True, then all the attachments that are supported by the function (PDF, PNG, JPEG/JPG, SVG, Word and Excel files) will be extracted as plain text.
If for your application the overall organization in sections is important, you can retrieve the markdown code using the parameter keep_markdown_format=True.
Confluence API to handle updates
After ingesting the data, you want to make sure that you keep your system with the most up-to-date information. The näive alternative would be to download all pages again and recreate the knowledge database. This approach is inefficient in terms of computational load and token processing demand.
To solve this problem we use a different strategy to update our knowledge base, which is checking which pages were actually updated. Through the Confluence API, we query the latest updated pages. Based on the information from this list we have two methods that can be used to update the information.
The first method is to use an auxiliary table in the database that tracks the last update date for each page. If there is a more recent entry on Confluence, then we extract the page again and update the content.
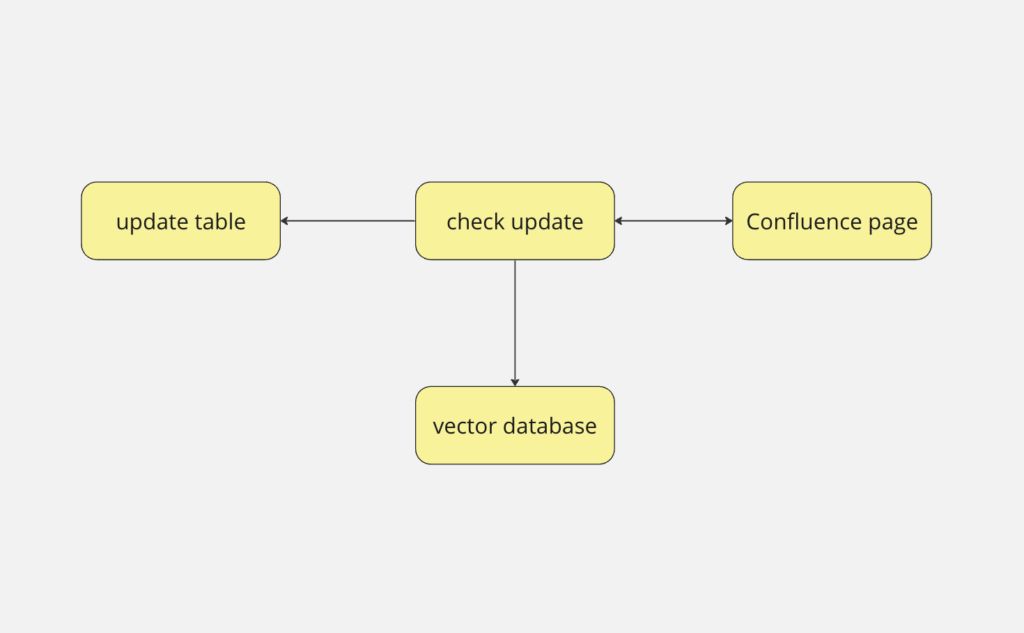
Another option is to traverse the list from the newest to the oldest register. Before saving, we compare the contents, e.g. by checking if there’s a difference between Confluence and our stored data. If that is the case, then we update the information and continue traversing the list. If not, then the algorithm stops.
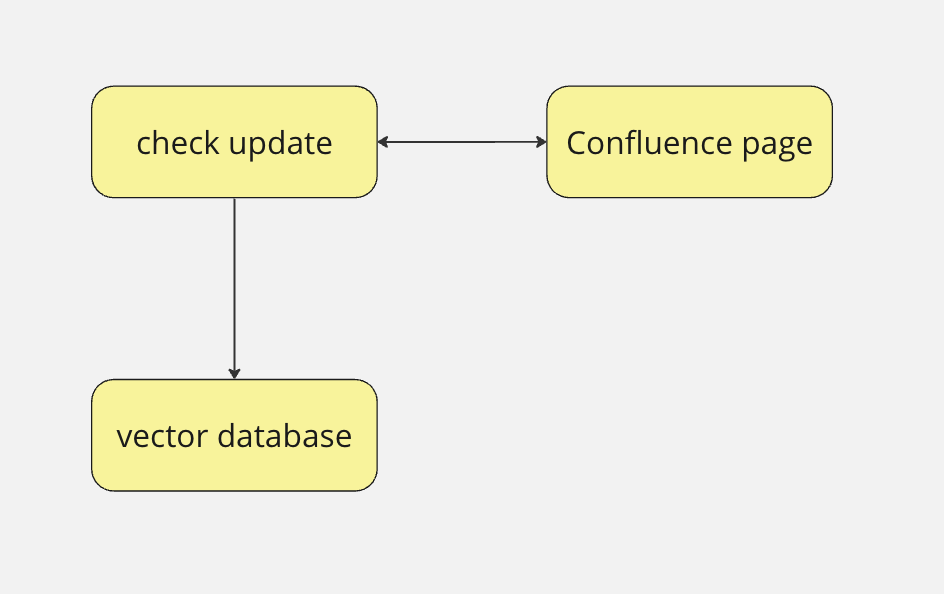
There is a tradeoff between memory and processing load between the first and second approaches, and you can choose what is best for your application.
Conclusions
Confluence stands as a formidable collaboration and documentation platform serving as the repository for vital company data. By integrating this platform as a data source for RAG systems, you unlock a whole new way to interact with your knowledge database: instead of looking for terms in the content and then digesting yourself until finding the answer to your question, you can directly ask the question on the search box and get the insights that you’re looking for.
Do you have a similar use case that you want to explore? At Arionkoder we’re experts in developing RAG applications for companies of any size and different industries. Contact us at [email protected] for a free consultation session and get ready to improve your decision-making process with this new technology!
Further resources
Here we compile some resources that might be useful for you in case you need to implement your custom Confluence integration: