
Retrieval Augmented Generation (RAG) tools are one of the most popular applications of Generative AI and Large Language Models (LLMs). They enable seamless access and retrieval of data from diverse sources. By just asking a question to a chatbot, a user can immediately receive a human-like response, and a series of relevant documents used to generate that answer.
Implementing these tools is not as straightforward as one might think. From connecting multiple datasets from different sources using a myriad of APIs to crafting an embedding database or prompt engineering a bot, these systems bring a series of challenges to the table (yet) without readily available plug-and-play solutions.
In this article I’ll focus on one of the most crucial components for developing RAG systems: establishing a rock-solid QA framework. We will first summarize the main features expected from these tools, the existing frameworks that are available for development, and explore a custom solution that we implemented for AK Bot, our own modular RAG platform.
Why QA frameworks matter
Ensuring a smooth transition from the development environment to production is crucial for maintaining a stable and reliable user experience. As products are limitless in their evolution and we keep adding new and new features to these tools, we need to guarantee that the previous things we’ve implemented remain working as smoothly as before while retaining their original accuracy.
The key tool to ensure this seamless integration is having a robust Quality Assurance (QA) framework. Here’s how QA frameworks prevent disruptive changes that could break a chatbot’s stability:
- Ensure consistency and reliability: A QA framework establishes standardized procedures and criteria for testing the chatbot’s functionality across different environments. In one of the RAG projects we’re working on, we have two different environments: Development (the one we use to check every new feature before release) and Production (the one that serves the actual users). This ensures that the behavior observed in development closely mirrors what users will experience in the production environment.
- Early issue detection: By systematically testing various aspects of the chatbot—such as its responses, integrations, and performance—QA frameworks can identify potential issues before they escalate to production. This proactive approach minimizes the likelihood of deploying a flawed chatbot version to users, which might seriously affect product traction and users trust.
- Enable regression testing: Changes introduced during development, such as new features or bug fixes, can inadvertently impact existing functionalities. QA frameworks include regression testing, which verifies that recent code modifications have not adversely affected previously working components of the chatbot.
- Compatibility and integration testing: RAG tools interact with diverse platforms, APIs, and databases. A comprehensive QA framework includes tests to verify compatibility and integration with these external systems, ensuring smooth communication and functionality.
The expected behavior of a QA framework
To effectively evaluate a RAG model, an approach that includes well-defined datasets of questions and answers is required. These datasets must encompass different types of questions to ensure an evaluation of the various features of the bot.
The key is to have a tool that, upon receiving the response from the RAG model, automatically determines whether it is correct or incorrect. This feature should be able to compare the response generated by the RAG with the expected response from the dataset, allowing us to measure the accuracy on that set (notice, though, that this is tricky, as answers are non-deterministic in GenAI, and might come posed in many different ways). This would then allow us to compare different development environments (such as production or development) and identify new errors or bugs in the RAG introduced as part of continuous development, ensuring that the system is robust and reliable for various usage scenarios.
Existing tools – and their limits
As in any development project, when we need to implement a QA framework for a RAG tool we first double check which tools are already available to this end. Our first attempt for our project was to leverage LangSmith, a development and management platform specifically designed for LLM-based applications. While it offers very interesting features for evaluating, debugging, and managing LLM applications effectively, we faced some challenges when implementing it:
- Dataset management was not straightforward: It was difficult to manage all the datasets needed for all the different features. Deleting or modifying existing datasets was something that we were not able to easily solve using the simplest version. This is natural for a tool like this, which is in its early stages of development and is constantly adapting to the use cases. But as we kept adding new features to our tool, we needed to solve this issue ASAP.
- Not very flexible pricing: Although Langsmith offers many different plans, it is difficult to find one that fits the exact needs of your project. As a result, you might end up paying a huge bill for a series of features that you don’t need. If your project requires a simple solution, it’s pointless to pay for a more complex one.
- Rigid prompting and accuracy computation: Langsmith offers a series of predefined prompts that enables to determine how good a chatbot is. While this is useful for early attempts, it gets too rigid if you need to do some tweaking on the prompts.
So, what did we do to solve this problem?
We faced these issues while implementing AK Bot, our RAG system deployed within our company to enable getting rapid insights from our organizational data. After considering different existing tools, we decided to implement our own solution, to have greater control over all the steps and features that we needed.
The main idea of our testing tool was to do as we said before: consider multiple datasets of user questions, evaluate the accuracy of the bot and make sure that every new feature does not break the previous ones.
By the time I wrote this article, AK Bot already featured:
- A connection with Atlassian Confluence, which enables it to answer questions regarding any page or document in the platform.
- A connection with Google Drive, which allows the bot to retrieve info from .docx, .pdf and slides files available in this cloud storage.
- A memory feature, which enables it to engage in follow-up conversations.
- A prompt injection prevention mechanism, to prevent malicious users from using the bot with a different intent to the one it was originally tailored for.
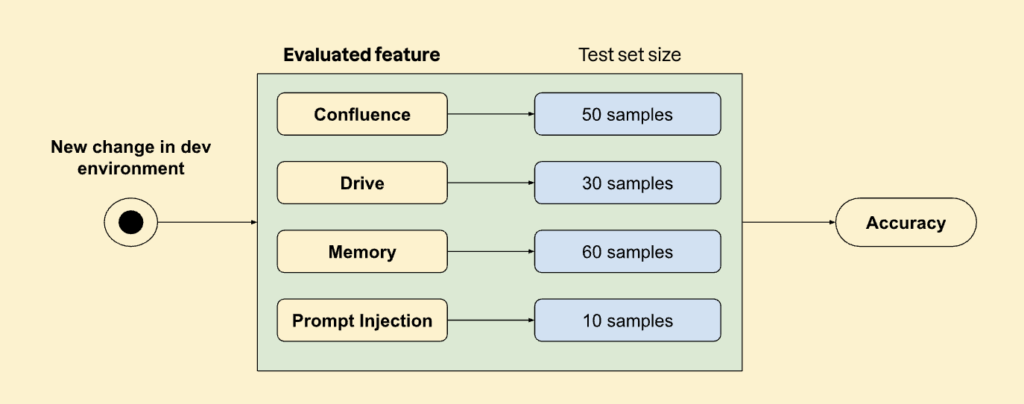
Calculating the accuracy
How do we know if an existing feature is working as expected?
The answer is quite simple: we carefully selected a subset of questions and answers that were correctly responded by the chatbot, so that we can compare correct answers with new answers.
You may wonder how we know if a new answer is the same or similar to the correct one.
We used LLMs for it. We created a prompt to compare two different answers, coping with the problem of GenAI not always answering the exact same text for a new question. This is an example of the prompt we used:
| You are a chatbot evaluator. Your main role is to identify if an output answer contains the same information as an expected answer. You will be provided the following information: – Question: question made by the user. – Answer 1: answer that the chatbot should return. – Answer 2: actual answer returned by the chatbot. Considering the input question you MUST respond with True if Answer 1 contains the same information as Answer 2. Otherwise you MUST respond False. |
Note: Data from different sources of information may be affected by changes such as modifications, or simply deletions. It‘s important to keep datasets updated so that accuracy is not adversely impacted.
Finally, the accuracy is calculated as the rate of correctly answered questions over the total amount of samples in the set:
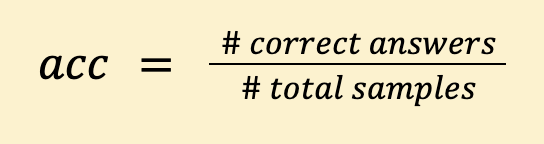
Conclusion
The implementation of a robust QA framework is not just a best practice but a necessity in chatbot development. It acts as a safeguard against unintended consequences of code changes, ensuring that the chatbot remains stable, reliable, and capable of delivering a seamless user experience. By prioritizing QA throughout the development lifecycle, teams can confidently deploy updates and enhancements that enhance rather than disrupt the chatbot’s functionality.
We can help you create and implement your own system today! Reach out to us at [email protected] and let’s push the boundaries together.