
Retrieval Augmented Generation, or RAG, stands out as one of the most revolutionary applications of Large Language Models. It enables the creation of knowledge retrieval systems that provide answers to direct questions input as free text, eliminating the need to sift through dozens of pages to find the information. Instead, thanks to the interaction of multiple AI-based components and data ingestion interfaces, a RAG system produces a human-like answer for you in a matter of seconds.
As we covered the fundamentals of this technology in our previous post, our goal today is to delve into the most important components of this tool and how they interact with one another. The following figure summarizes the scaffolding supporting a RAG system:
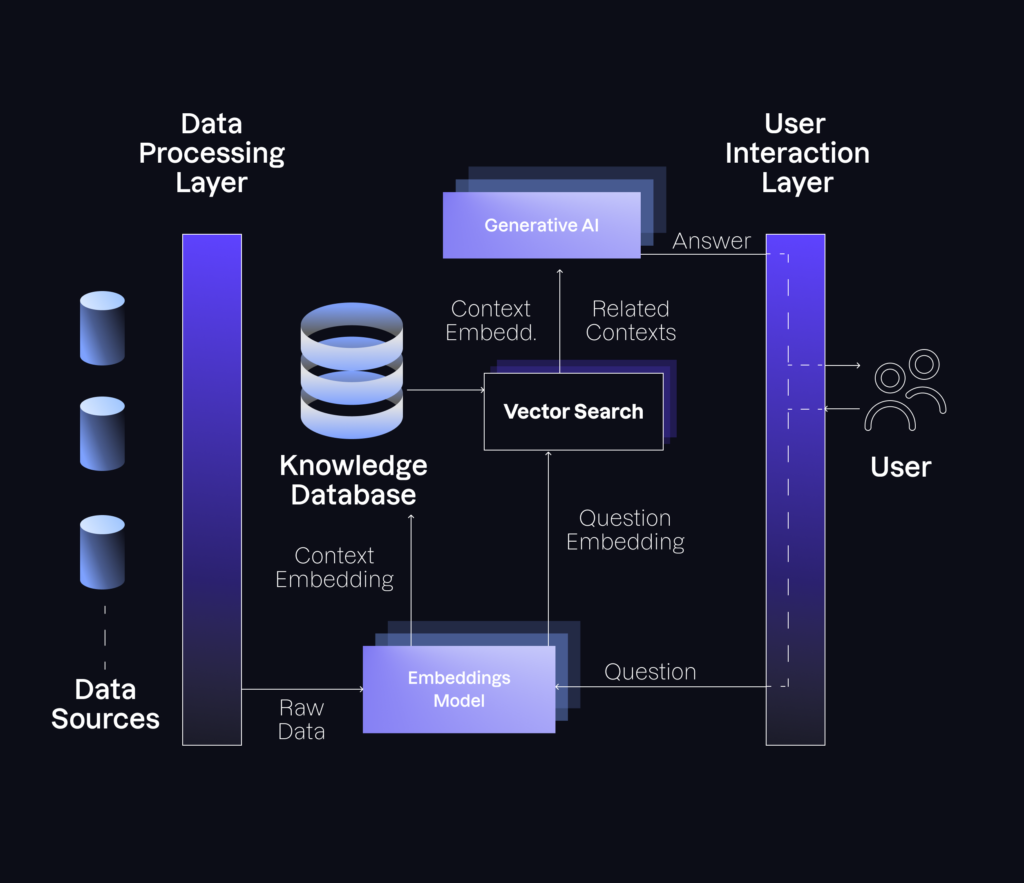
Given a series of data sources (e.g. PDF files on a Google Drive folder, multiple websites of interest, pages in Confluence or Notion, etc.), the RAG system periodically accesses them to decompose all their content into a series of raw pieces of overlapping text, known as “contexts”. This process is handled by a data processing layer, which is usually custom-made for each particular system.
Contexts are then fed to the first AI component of a RAG tool, the embedding model. In a nutshell, this is nothing but a neural network that takes text as input and outputs a list of numbers describing the semantics of it. Think of it as an index of a dictionary, but amped up. Rather than sorting text in alphabetical order, it summarizes it based on its actual content.
This vector representation has an amazing mathematical property: if you measure the distance between the embeddings of two related pieces of text, you will get a low number; conversely, if the contexts you are comparing are unrelated to one another, you will get a high value. Hence, this enables a whole new way of looking up text. Thus, if we want to find something, we no longer need to seek exact terms, but instead find those pieces of text whose semantic representations live at a short distance from the input.
Based on this characteristic, RAG systems build a knowledge database, a digital space in which every context is associated with its own embedding. Every time a user inputs a question, this is processed by the same embedding model to extract its vector representation. Subsequently, a vector search engine is used to identify a predefined number of related contexts simply by measuring the distance between the embedding of the question and the embeddings stored in the knowledge database. After finding the contextual information, a generative AI is fed the input question and the contexts using a pre-defined prompt that remains invisible to the final user. Thus, the AI crafts a human-like answer to the question based on the given contexts, almost instantly.
Interaction usually occurs through a user interaction layer, which interfaces different input mechanisms. It could be a connection to a custom-made portal, or the chat box in your own website, or even a connection to the API of a third-party chat system like Microsoft Teams or Discord. In our internal RAG system, for example, this layer features a connection to Slack. Hence, Arionics ask questions to our bot through this communication channel, and the back-end processes it just as we explained before to provide the answers that they seek.
As straightforward as it sounds, implementing a RAG system requires taking multiple factors into consideration, including principled data connections, security measurements, properly choosing the right LLMs, designing the right prompts, and ensuring efficiency for a seamless experience. In upcoming articles, we will dive deeper into each of these elements, highlighting the challenges to face and how we have solved them in the past for our customers.
Do you want to have your own RAG system? Wondering how to leverage this technology for your business? Don’t hesitate to reach out to us at [email protected] for a free consultation. And stay tuned for more insights in our upcoming content releases!