
Introduction and Motivation
An AI Companion can be understood as a system that simulates human interaction to provide companionship and emotional support, with a promising application in assisting older adults. While they can stay in touch with loved ones through digital platforms, many seniors still feel isolated and uncertain about technology. An AI Companion could help by listening to their life stories, offering quizzes or games for fun, suggesting and facilitating calls to family members, providing reminders, sharing interesting facts or news, or simply engaging in friendly conversations.
At the same time, we must ensure it doesn’t lead to more isolation, just like other modern technologies sometimes do. Such a system involves addressing delicate or sensitive topics, considering psychological and ethical factors, and evaluating political implications. To manage its complexity, the project must be broken down into smaller steps, ensuring that each component contributes to an overall experience that truly benefits its users.
From Basic Chatbots to Vector Databases
First, we can use an approach where we implement the simplest possible version and then evolve from there. A clear simplification of an AI Companion could be an AI Assistant that deals only with factual information, not sensitive matters, feelings, or empathy. An even simpler version would be an AI Chatbot. Following this idea, we can start by implementing the foundations of a system that will become increasingly complex over time.
In all three cases, the user is a person. Considering an AI chatbot that can answer questions and store information about someone’s life (like parents, friends, hobbies, and so on), we arrive at the need for long-term memory storage. We could initially consider relational databases, but we can’t predict their structure for every use case. Well-known non-relational databases might work, but they’re not ideal if we want to store any relevant information the user provides with the possibility of a very dynamic retrieval. That leads us to the need for vector databases.
We can store texts as memories with vector databases and perform semantic retrieval to find data by similarity. This similarity calculation depends on using an embedding model, transforming data into numerical representations, to retrieve the most likely relevant information. So, we can store a simple chatbot conversation like:
role: “user”
session: “user123”
text: “My dog name is Pucky”
role: “user”
session: “user123”
text: “Do I have a dog?”
role: “assistant”
session: “user123”
text: “Yes, you have a dog named Pucky! If you have any questions or need tips about caring for Pucky, just let me know!”
Here, we can ‘ask’ the database about what the user requested and get the best answer by similarity, which is returned to the user using the RAG pattern → the so-called Vector Based RAG.
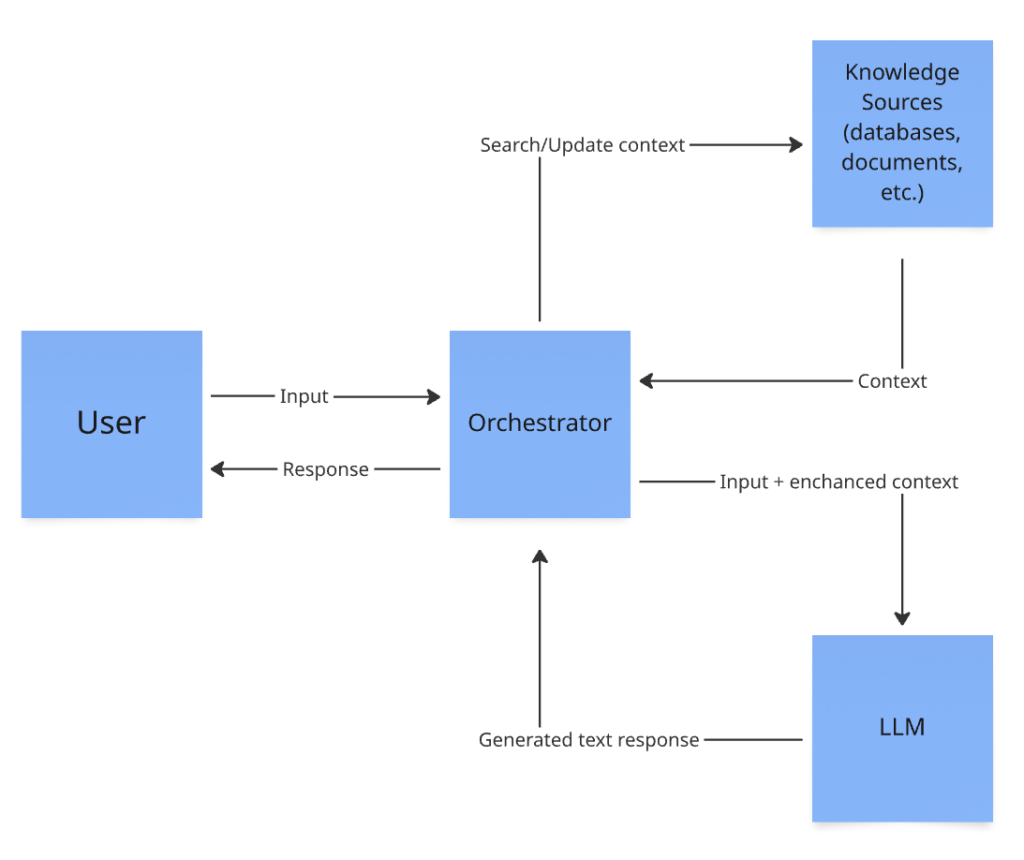
Expanding Context with GraphRAG
This architecture can work very well for simpler ChatBots that deal mainly with facts and text without much interconnection of content. However, considering that our ultimate goal is to build an AI Companion for the elderly, which must work more effectively and efficiently, we need a way to store entities and relationships, similar to what we do with relational databases, but in a more flexible and dynamic way. Additionally, even though using RAG with vectors increases the chance of a correct response, it occasionally still lacks context, as well as certain factual information. It also doesn’t give much insight into how a specific decision was made or why a certain answer was given. With all these factors in mind, we can look at the world of knowledge graph databases.
Graph databases are a type of NoSQL database specialized in storing information in graph form, using nodes to represent entities (places, people, objects, etc.) and edges to represent relationships between them. This allows us to better represent the ontology of a specific use case in a way that is more easily understood by machines and humans alike.
When working with graphs, we can use certain Organizational Principles. These are ways to guide us in structuring a specific domain faithfully based on concepts and rules. In graphs, an organizational principle can be the categorization of entities and relationships for our particular use case. We can represent these as nodes and edges. For our AI Companion case, we need to define organizational principles that faithfully represent a person’s life and relationships more efficiently.
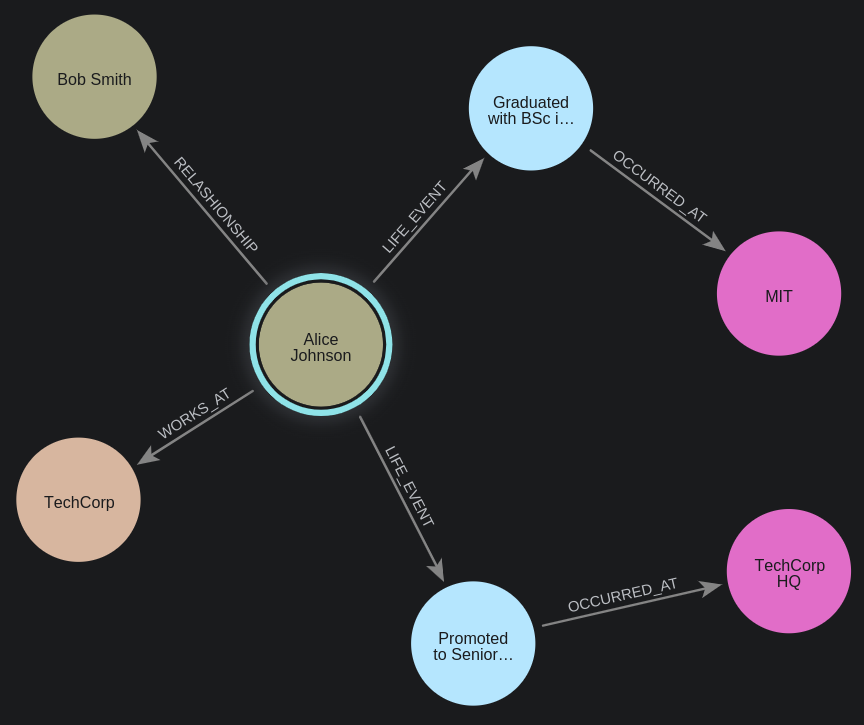
However, using graphs doesn’t mean we stop using vectors; the two approaches complement each other. The architecture will remain essentially the same, but this new database will be included in the flow. We can store graphs and vectors in separate databases or use a unified graph solution supporting vector searches. A basic GraphRAG pattern is as follows:
- Use vector or keyword search to find an initial set of nodes.
- Traverse the graph to gather information about related nodes.
- Optionally re-rank documents using a graph-based ranking algorithm like PageRank.
We can see that a solution relying solely on a vector database for an AI Companion wouldn’t be complete or sufficiently effective. With GraphRAG, compared to a purely vector-based RAG, we gain several advantages:
- Significantly more accurate and relevant answers
- Reduced token usage
- Greater scalability
- A visual representation that is more understandable and traceable
- Easier to audit
- Enhanced security and privacy
Focusing more on security, which will be essential in our AI Companion application, we can more easily restrict access to certain nodes based on permissions, something not so ideal to do using only vectors.
Additionally, by using graphs, we can define not only nodes and relationships but also properties of each entity. Consequently, it’s important to establish the characteristics relevant to every category or domain we wish to represent – the Organizational Principles.
Onboarding and Data Integration
Still, we need a way to feed data and information into our database beforehand, rather than just dynamically populating it with user inputs. In this sense, having an onboarding system is crucial. During onboarding, we create the graph with the main nodes and edges of the individual’s life, then evolve it as the system is used. We need to understand how to build a graph, specifically a domain graph for our use case, a “social graph.” We will have two main sources for graph creation and evolution:
- Structured data from the onboarding process
- Unstructured data from relevant information occasionally found in user inputs
The choice of technology is flexible; what really matters is recognizing that there are tools available to help populate our future graphs, rather than doing everything manually. Specifically, for unstructured data, one option is to use Named Entity Recognition (NER), a technique focused on identifying and extracting entities and structured elements from text, to avoid inconsistencies when creating graphs and relationships. While we could simply rely on LLMs for this purpose, their accuracy might not match that of specialized, pre-trained NER models. Some well-known tools for it are SpaCy and Stanford NER.
Next Step: MCP Servers
However, given the need to create a “version zero” of an AI Companion within a tight deadline, we look at all these concepts and might encounter significant technical complexity and coding effort. This is where the concept of MCP Servers comes into play, a development that has been revolutionizing the AI world.
Basically, the Model Context Protocol (MCP) is an open standard that allows AI models to interact with various data sources and tools. It gives AI applications the ability to access, input, and modify information from a wide range of systems, such as Slack, GitHub, Confluence, databases, and many more. Because of its power, MCP Servers become an extremely useful component for our AI Companion use case. Explore our in-depth MCP Servers article: The Power of MCP Servers: Revolutionizing AI Tool Integration.
By integrating an MCP Server for our chosen database, we can easily connect it with an AI-driven backend and drastically reduce the coding effort needed to model, create, and evolve the data structure. For instance, we can create an Agent responsible for generating database models and queries based on our inputs and then executing them through the integrated MCP Server. It can even handle heavier tasks like searching and updating graph nodes and relationships over time. Here is an interesting article showcasing how Claude integrates with Neo4j via MCP: Knowledge Graphs, Claude, and Neo4j with MCP.
Final view
In order to carry out an initial validation of graph creation, I conducted tests integrating Pinecone as a vector database, Neo4j as a graph database, OpenAI models, and SpaCY NER. It all worked perfectly for storing and retrieving user information semantically.
A final consistent approach for a demo would look like the following:
- The user inputs a text like: “My name is Pedro and I have a dog named Pucky.”
- We use an embedding model to transform the text into its numeric representation.
- Upsert the created vector into Pinecone or another vector DB
- We make an LLM call or use NER to get possible nodes and relationships from the user input, along with the final query to the Graph DB
- Upsert the extracted data into the Graph DB
- (Alternatively, use an MCP server integrated with an agent to get the nodes and update the graph DB)
- The user inputs a text like: “What’s my dog’s name?”
- We embed the text again and use it to search for the most relevant info in the vector database
- We make an LLM call or use NER to get possible nodes and relationships from the user input, along with the final query to the Graph DB
- We make an LLM call with both the vector DB and GraphDB responses as context, in order to create a viable response to return to the user: “Your dog’s name is Pucky!”.
If you want to test it yourself, check out the Github Repo below and follow the instructions in Readme: https://github.com/PMafra/my-ai-bro