
Biological vision systems are intricate creations that have evolved over millennia. At their core, they consist of two fundamental components: sensors (our eyes) and a processing unit (the brain). When light enters our eyes, our retinas convert this light into electrical impulses, which travel through the optic nerve to the brain, where we interpret these signals as images.
For years, researchers have sought to replicate this process through computer technology. In this context, the sensors are not our eyes but image acquisition devices—such as smartphone cameras, satellites, or X-ray machines. The processing unit? That’s where computers come into play, mimicking our early learning experiences as they decipher the content of images.
This fascinating area of study is known as Computer Vision. It involves developing algorithms that allow machines to automatically extract information from images. While computer vision has been a subject of research across various disciplines like physics, mathematics, and biology, its true potential began to shine with the advent of Machine Learning. More recently, the implementation of Deep Neural Networks has further advanced this field, enabling us to harness the vast amounts of visual data available to train deep learning models for a variety of tasks.
Key Applications of Computer Vision
While each computer vision application is unique, they generally rely on models that automate tasks such as image classification, object recognition, semantic segmentation, and image generation. Here’s a closer look at these applications:
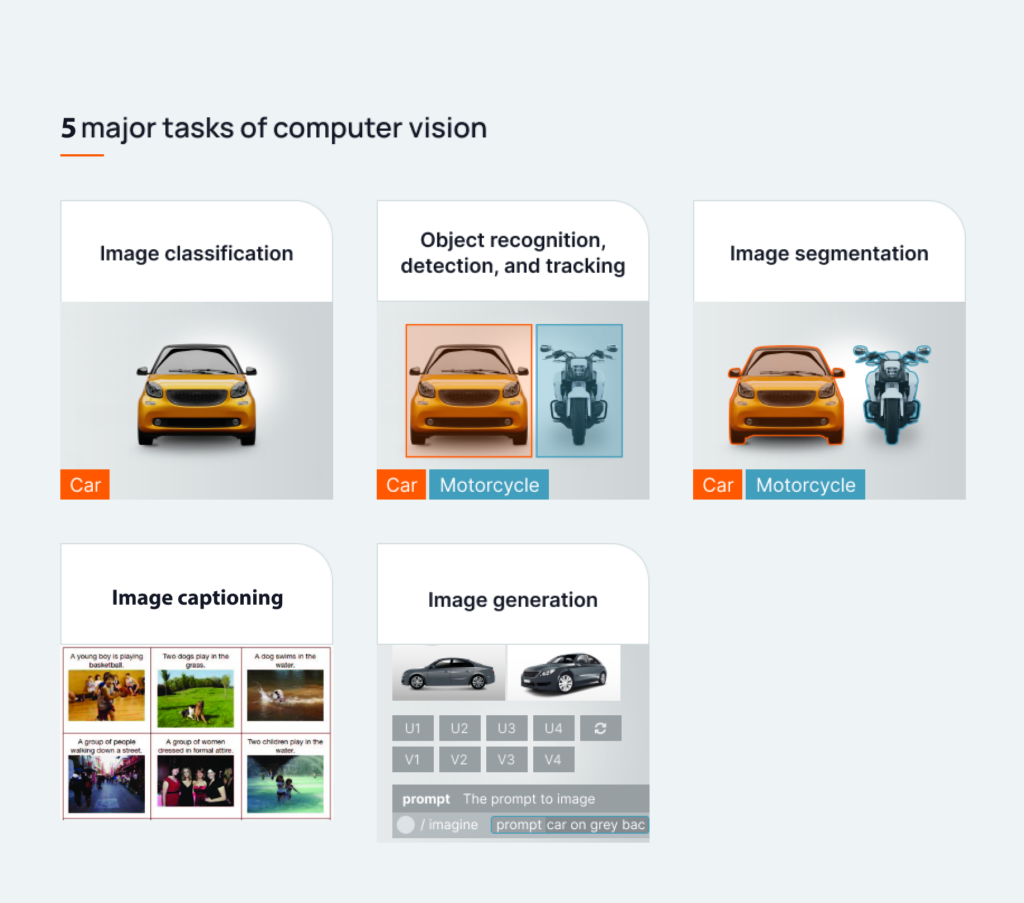
Image Classification
This involves automatically assigning one or more predefined categories to an input image. Convolutional Neural Networks (CNNs) were initially designed for this purpose, effectively classifying scanned digits for Optical Character Recognition (OCR). More recently, the same neural network architectures used for GPT-like models, the so-called Transformers, have been adapted also to incorporate vision capabilities. Both families of models can now categorize photos based on their content, recognize faces in security footage, and even detect diseases from medical images. Image classification models are trained on large datasets containing labeled images, allowing deep neural networks to identify patterns and make informed decisions about new images. In the past, we have used off-the-shelf pre-trained models to overcome the data labeling problem, enabling us to quickly extract valuable pieces of information from complex medical reports in a matter of seconds, for downstream applications such as treatment recommendations.
Object Recognition
Going a step further, object recognition models not only classify images but also draw bounding boxes around each detected object, identifying their classes. Popular deep learning networks like YOLO and Faster R-CNN can perform these tasks in natural images in less than a second. Applications include detecting lesions in medical scans, identifying individuals in surveillance footage, and powering self-driving algorithms, such as Tesla’s AutoPilot. In previous projects we have, for example, used object recognition models to automatically identify specific sections in contracts and medical reports, in which we applied later OCR techniques to transform images into text.
Semantic Segmentation
If a more precise representation of an object is needed, we turn to semantic segmentation. Here, a neural network classifies each pixel in an image into specific classes, creating masks that approximate the actual shapes of objects. This technique is invaluable in various fields, aiding clinicians in treating brain tumors, extracting information from satellite images, or even altering backgrounds in video calls. U-Net models are particularly effective for biomedical image segmentation, while models like DeepLab-v3 excel in processing natural images, albeit requiring larger datasets. With the recent implementation of open-source foundational models such as Segment Anything (SAM) by Meta, we can now go one step further and excel in challenging applications even under data scarcity. We have helped companies in the past to exploit these models to accelerate developments around skin lesion segmentation, and we have experimented with this model in basic research applications such as viral titration.
Image Generation
This innovative area focuses on creating artificial images from scratch, sometimes using nothing but text prompts! Generative Adversarial Networks (GANs) were once the stars of this field, powering social media filters and apps. However, diffusion models have taken the lead, showcasing impressive capabilities in generating images and videos, such as OpenAI’s DALL-E 2, Stable Diffusion and Midjourney. These tools are transforming art, graphic design, and cinema, enabling artists to bring their visions to life more efficiently than ever. In Arionkoder we exploit these tools almost anytime that we need a new graphic resource: from graphic design for websites and marketing campaigns to ideation processes and discoveries.
Image Captioning
All recent advancements in Transformer-like architectures have revolutionized the field of image captioning, in which a model automatically produces text from an input image. Thanks to these techniques, you can now bypass the need of some intermediate steps like image classification or object detection, as a GPT-like model with vision capabilities can now describe the content of the image automatically. We have used this technique to transform complex unstructured data such as images and tables in text into summaries that we can then process using Retrieval Augmented Generation tools. Furthermore, we have experimented with this approach for implementing Wizard of Oz prototypes, showcasing fully functional vision applications while training the actual models that will support them.
As you can see, our team of PhD Computer Vision experts at Arionkoder is ready to help you unlock the potential of your image data. Whether you’re looking to improve efficiency or explore new innovations, we’re here to push the boundaries with you. Reach out to us, and let’s start this journey together, at [email protected]!