In this article, we cover the essentials of computer vision and briefly summarize some of the great things we can do empowered by this technology.
By José Ignacio Orlando, PhD, Assistant Researcher @ CONICET and Nicolás Moreira, Head of Engineering @ Arionkoder
Biological vision systems are complex structures that have been developed throughout millennia of evolution. Briefly, they are based on the interaction of two fundamental elements: a sensor (which is, in our case, the eyes) and a processing unit (i. e. the brain). Thus, when light reaches our eyes, our retinas transform this signal into electrical pulses that are then transmitted through the optic nerve to our brains, where they become images that we can interpret and use to make decisions.
For many years, researchers have explored multiple ways to mimic this process using computers. The sensors in this case are not our eyes but image acquisition devices, either the cameras in our phones, a satellite, or an X-ray machine. And what about the processing unit? Well, that’s the computer, which, as we did when we were children, will need to learn what the actual content of the images is.
This is known as Computer Vision: a field of computer science in which we develop algorithms to automatically mine information from images. While this field has been extensively studied in the past -building on top of multiple disciplines like physics, mathematics, and biology- it was not until the application of Machine Learning that we started to see the actual impact of this technology. More recently, the application of Deep Neural Networks has boosted the field even further, letting us leverage the increasing amount of images we have access to in order to train deep learning models that automate several tasks.
While every computer vision application is unique on its own, they usually rely on one (or many) models that automate image classification, object recognition, semantic segmentation or image generation, among others. Hence, Computer Vision experts usually analyze any new problem they face and try to see which parts of it can be automated using any of these techniques.
Image classification refers to the task of automatically assigning one or multiple predefined categories to a given input image. Convolutional neural networks, a family of models within the deep learning realm, were originally designed for this kind of problem, especially to classify scanned digits. With all the engineering advancements in crafting new and more powerful elements for these architectures, now we can use these models not only to assign categories to photos based on their actual content but even face recognition on security footage or automatically detecting diseases from images.

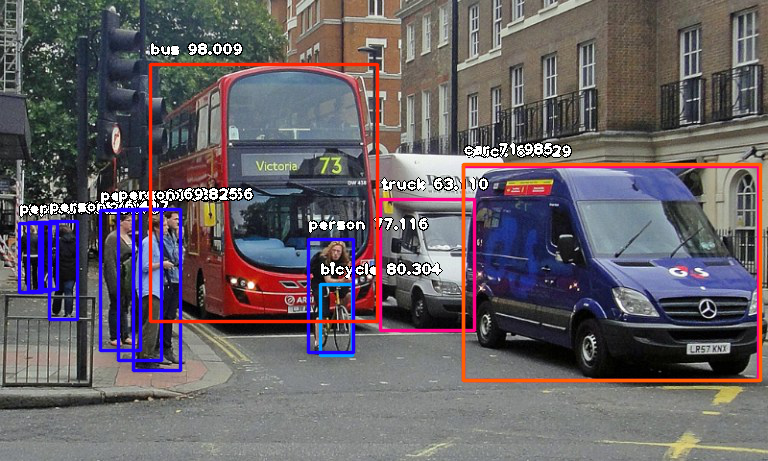
Object recognition goes one step further: instead of assigning a global class to the image, these models generate a bounding box around every observed object of interest and determine which class of object is contained within its edges. Popular deep learning networks such as YOLO and Faster R-CNN can effectively do this in natural images in less than a second. As a result, these models are applied to detect lesions in medical images, identifying persons of interest in surveillance footage or at the core of self-driving algorithms such as AutoPilot in Tesla cars, to name a few.
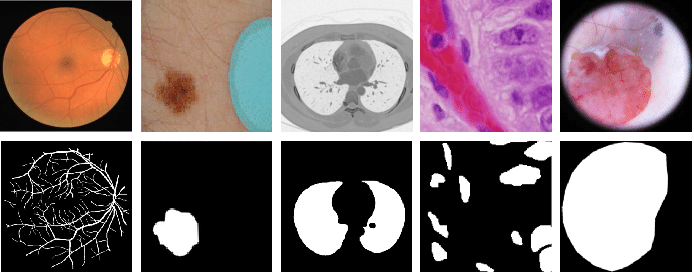
But what if we need a more accurate approximation of the object, beyond a simple box surrounding it? Well, then we are facing a semantic segmentation problem, where a neural network will classify each pixel into a class of interest. As a result, we get masks approximating the actual shape of each object in the image, like when we use the magic wand in Adobe Photoshop. This renders useful for aiding clinicians to treat brain tumors, quantifying information of interest from satellite imagery or changing backgrounds in Google Meet. U-Net models are widely popular for segmenting biomedical images, as they can be trained with less amount of data and still produce remarkable results. Other popular models such as DeepLab-v3 are effective for processing natural images, although requiring larger amounts of training data.

Finally, image generation stands for a whole area of computer vision in which the purpose is to produce artificial images out of… sometimes nothing! Generative adversarial networks (GANs) were quite popular a few years ago, and are still at the core of social media filters and apps for aging your face. More recently, diffusion models have certainly debunked them, demonstrating an outstanding performance for producing artificial images and videos from text prompts, like OpenAI’s DALLE-2 or Stable Diffusion. These tools are revolutionizing art, graphics design and cinema, helping artists bring their ideas to life in a much more efficient way than before.

In future blog posts, we will cover each of these applications in more detail, to discuss some of the great things that might be accomplished using this technology.
In Arionkoder we have teams of Computer Vision experts who are ready to help you make the most out of your image data! Contact us here, and let’s accomplish great things together!